OpenAI的競爭者Anthropic發表的最新人工智慧研究論文〈Decomposing Language Models With Dictionary Learning〉,提出一種稱為字典學習的方法,增加對神經網路的解釋性。這項研究讓Anthropic更能夠監控模型,進而引導模型的行為,提高企業和社會在採用人工智慧的安全性和可靠性。
由於神經網路是以資料進行訓練,而非根據規則的程式設計,每一步訓練,都會更新數百萬甚至數十億個參數,最終使模型得以更好地完成任務,但Anthropic提到,雖然研究人員可以理解訓練網路的數學運算,但是卻不真正明白模型是如何從一堆數學運算中,導出最後的行為。而這樣的狀況,使得研究人員很難判斷模型出現的問題,而且也難以進行修復。
雖然現今人類已經進行了數十年的神經科學研究,對於大腦的運作有了深入的了解,但是仍然有很多大腦中的謎團尚待解密。類似的情況,人工神經網路也存在難以完全理解的部分,只不過與真實大腦不同,研究人員可以透過實驗來探索其中的運作機制。
儘管如此,過去對神經元的實驗並沒有太多幫助,研究人員透過干預單一神經元,觀察該神經元對特定輸入的反應,他們發現,單一神經元的活化,與神經網路的整體行為並不一致。在小語言模型中,單一神經元會在英語對話、HTTP請求或是韓語文本等不相關的上下文都很活躍,電腦視覺模型中的同一神經元,可能會對貓臉和汽車都有反應。也就是說,在不同的情況下,神經元的活化可以代表著不同意義。
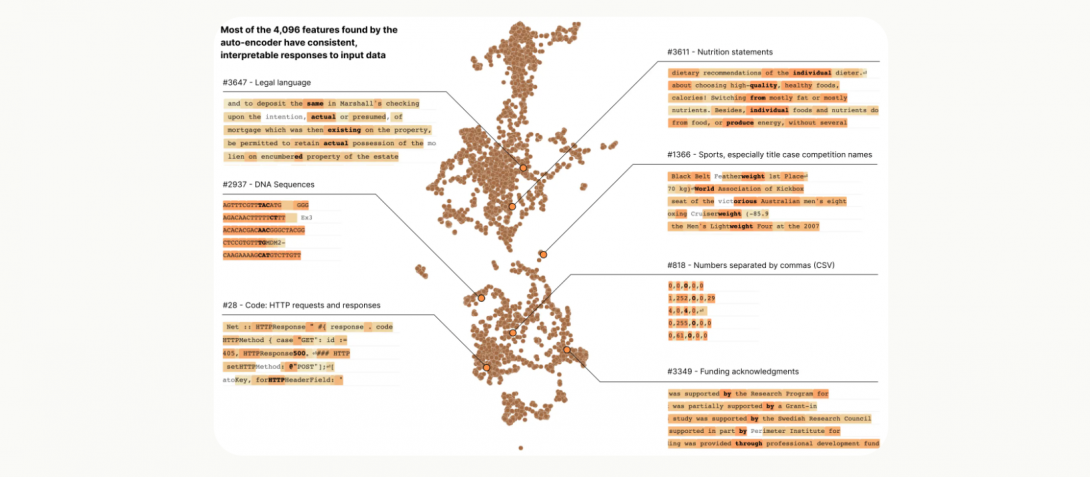
在Anthropic最新的研究中,研究人員擴大分析單位,不在單一的神經元中尋找規律,而是運用一種稱為特徵(Feature)的概念。每個特徵都會對應一群神經元活動模式,這為研究人員提供了新的分析途徑,能夠將複雜的神經網路解構成更容易理解的單位。
在Transformer語言模型中,研究人員成功將一個包含512個神經元的層,分解成超過4,000個特徵。這些特徵涵蓋了DNA序列、法律用語、HTTP請求、希伯來文和營養標示等範疇。此外,研究人員也確認了特徵的解釋性遠比單一神經元更高。
論文中也提到,研究人員發展了自動解釋方法,來驗證特徵的可解釋性。藉由大型語言模型來生成小模型特徵的描述,並以另一個模型的預測能力對描述進行評分,而實驗結果證實,特徵的得分仍高於神經元,如此便證實了特徵的活躍和模型下游行為具一致性。研究人員還發現,在不同模型間所學到的特徵大致通用,因此一個模型從特徵得到的經驗,可能適用於其他模型。
這項研究的貢獻,在於克服單一神經元的不可解釋性,透過將神經元分群成特徵,研究人員將能夠更好地理解模型,並且發展更具安全性和可靠性的人工智慧服務。未來Anthropic研究人員會擴大研究範疇,理解大型語言模型的行為。